- 2016-03-21 13:40〜18:20
- 東工大 西8 W809
- https://facebook.com/events/494071657461395
家を出るのが遅くなって目黒乗り換えにミスってトータル9分ロスしてゆっくり昼飯くう時間はなさそうで、駅前のマックで100円x2で腹ふくらかそうとしたら人があふれてたので、大岡山駅前のスーパーでおにぎり2個で昼食205円。しかし205円で320kcalは少なかった失敗。
どうやら応用物理学会(JSAP)をやっているようでキャンパスはダークスーツ集団で埋めつくされていた。かなり規模でかそう。


西8号館のエレベータ乗ったらE棟だったらしくエレベータおりてすぐ土禁になっててびっくり引き返す。3階にひきかえしてW棟のエレベータの乗って8階へいくとまだ部屋が開いてなかったのでリフレッシュルームでおにぎりもぐもぐ。天気がよくなってきて見晴らしがよい。






[2016-03-21 13:38]
- 首藤さん前説

[2016-03-21 13:41]
SensorBeeの紹介 / 柏原秀蔵 (@suma90h) (PFN)

- http://www.slideshare.net/suma_/sensorbee-59828977
- bit.ly/distributed2_sensorbee
- ネットワークエッジでストリームデータを機械学習
- ETL: extract(前処理) transform(加工) load(DBなどに書き出し)
- storm norikra sparkなど
- BQL (sql like language)でfilter,aggregate(平均とか),join(複数のストリームの結合とか)できる。
- LIDAR(ライダー)は可視光カメラと併用されていくのではないか。
- source/sink/state/stream
- 状態をもてる(user-defined state)
- ETLツールなので分散システムというわけではない。
- UDF/UDSはstaticlink。だいたい30MBくらいになる。Go言語。
- 実行の種類: run,runfile,shell,topology,... (マイクロサービスっぽい感じ)
- python C-APIがハマリポイントだった。いろいろメンドクサイらしい。
- JavaのJNIは重いかわりにつかいやすかった(首藤)
- http://sensorbee.io
- Q: BQLからつくられたグラフはどう処理されているのか?
- A: パイプで非同期に動いているとおもう。
- Q: UDF/UDSのとっかかりは?
- A: goで書く。pythonでも書ける(基本オブジェクトのやりとりしかできない)。
- Q: wc
- A: UDSが必要。
- Q: 耐故障は?
- A: キューが伸びるとドロップする。マシンが落ちたらおわり(作り込んでない)。
- Q: なぜgo?
- A: 社内がgo。C++はいや。静的コンパイルしたい。
- 静的リンクはあり。
- JITコンパイラは実地での再現がめんどくさい。(首藤研で研究中)
- chainer連携
- BQL: source=opencv sink=fileというのを簡単に書ける。opencvを書かなくてもよい。
- tee的なUDFがオフィシャルにあればデバッグにいいかも。
- 分散処理にする予定はない。
- sinkとsourceをfluentdでつなぐとかは、最悪あり。
- 人物検出をCPUでやってて遅い(i5)。FHDで15fps。
- フロー制御はない。Javaで標準化しようとしている。(reactive stream?, NETFLIX:reactive socket?) なぜHTTP2じゃない?とか
- PFIは投資をうけない、PFNは投資をうけるために分けた。IとNは関連会社。
[2016-03-21 15:04]
休憩

[2016-03-21 15:30]
分散処理と関数型プログラミング / 岡本雄太 (@okapies)

- https://speakerdeck.com/okapies/distributed-system-and-functional-programming
- 東工大の授業でJavaからScalaに変わったらしい。
- Scala: ネットワークプログラミングや分散につかわれている。
- Steve Yegge の Google とプラットフォームに関するぶっちゃけ話を訳した(前編)
- 分散システムをなぜやるか: スケーラビリティ・耐障害性・組織(マイクロサービス)NEW!
- マイクロサービスアーキテクチャの特性を2つに分けると:
- 組織の特性(目的)
- 技術の特性(手段)
- Conway's Law (軍事組織のソフトウェア開発の研究) 組織の構造がソフトウェアの構造に反映される。
- SOA(service-oriented architecture)は失敗した。ESB(enterprize service bus)はスマートなパイプを実現しようとした。
- マイクロサービスでは賢いエンドポイントと愚かなパイプ。
- SOAとESBの違いはトップダウンかボトムアップの違いではないか。(みずほはSOAらしいが..)
- 強いモジュール境界・独立した配備・技術的多様性
- 分散オブジェクト設計の第一法則: オブジェクトを分散させるな。
- マイクロサービスのコスト: 分散・結果整合性・運用の複雑さ
- ネットワークレイテンシの壁: googleサービスを日本で使うのと西海岸でつかうのとで体感速度が違う。
- kumagi:asyncとnon-blockingをつかいわけよう。
- 同期呼出で待ち時間がもったいない→コールバック→地獄/破滅のピラミッッド
- 分散と関数型プログラミングでモジュール化が簡単になる(実用的にはモジュール性を高めるための手法)
- モジュール性を高めるためにOOは状態をカプセル化した。FPは状態をなくした(状態はモジュールの境界に置く)。
- composabilityが鍵。そのために数学的な手法をつかう。
- 外界←→副作用あり→副作用なし
- 糊: 高階関数(コンビネータ)と遅延評価
- 問題を分割する方法は解と解を貼り合せる方法に... (quickcheckの作者...)
- whatとhowの分離: whatはDSLで記述、how(ランタイム)で解釈実行。 → SensorBeeのBQLがDSLに相当
- (...モナド...)
- Future/Promiseもモナド
- 成功・失敗: RPC失敗したらmapで関数適用してくれない便利なやつらしい
- scalaだと: futureはreadonly, promiseだとwritable。言語によりまちまち。
- 便利なやつ: map, flatMap, sequence.
- val userAndTweets = Future.join(userService.findByUserId(userId), tweetService.findByUserId(userId))
- RPCだから副作用は発生しているが、プログラマ視点では副作用がない純粋な記述になっている。
- 失敗からの復帰はrecoverを書く。
- タイムアウトは別途書く必要がある。
- マイクロサービス向けフレームワーク
- Netflix OSS
- Twitter Finagle(フィネーグル), Zipkin, etc..
- finagleがつかえるからscalaをつかうという流れ
- your server as a function: futureとservice,filterの組み合わせでサーバを記述する。
- service: requestをうけとってresponseを返す関数
- filter: requestとserviceをつけとってresponseをつつんだfutureを返す。
- これってデータフロー処理?
- FRP(reactive extension)
- Akka streams: actorベースの上でデータフロープログラミング
- FlowGraph DSLという、きもちわるい記述がある 〜>
- Rubyは動的にメソッド定義できるところがDSL向き(首藤)
- 業界標準のデータフロー定義の流れ: Apache Dataflow (apache Beam)

[2016-03-21 17:28]
休憩



[2016-03-21 17:39]
分散データストアの因果整合性違反度測定手法 / 高塚康成

- データ間の依存関係の整合性は保証しないんものがほとんど。
- 保証するのにDBがやるかミドルウェアがやるか。アクセス性能が低下してしまう。
- そもそもどのくらい因果整合性が違反している頻度はどのくらいなのか? → 測ってみた。
- アクセスログで測定する手法の提案。
- これまでに読みだしたデータが依存するデータより古いバージョンを読み出してしまったかどうかをチェックする。
- 依存関係グラフ: write-after-write(同一クライアント) or write-after-read(任意クライアント)
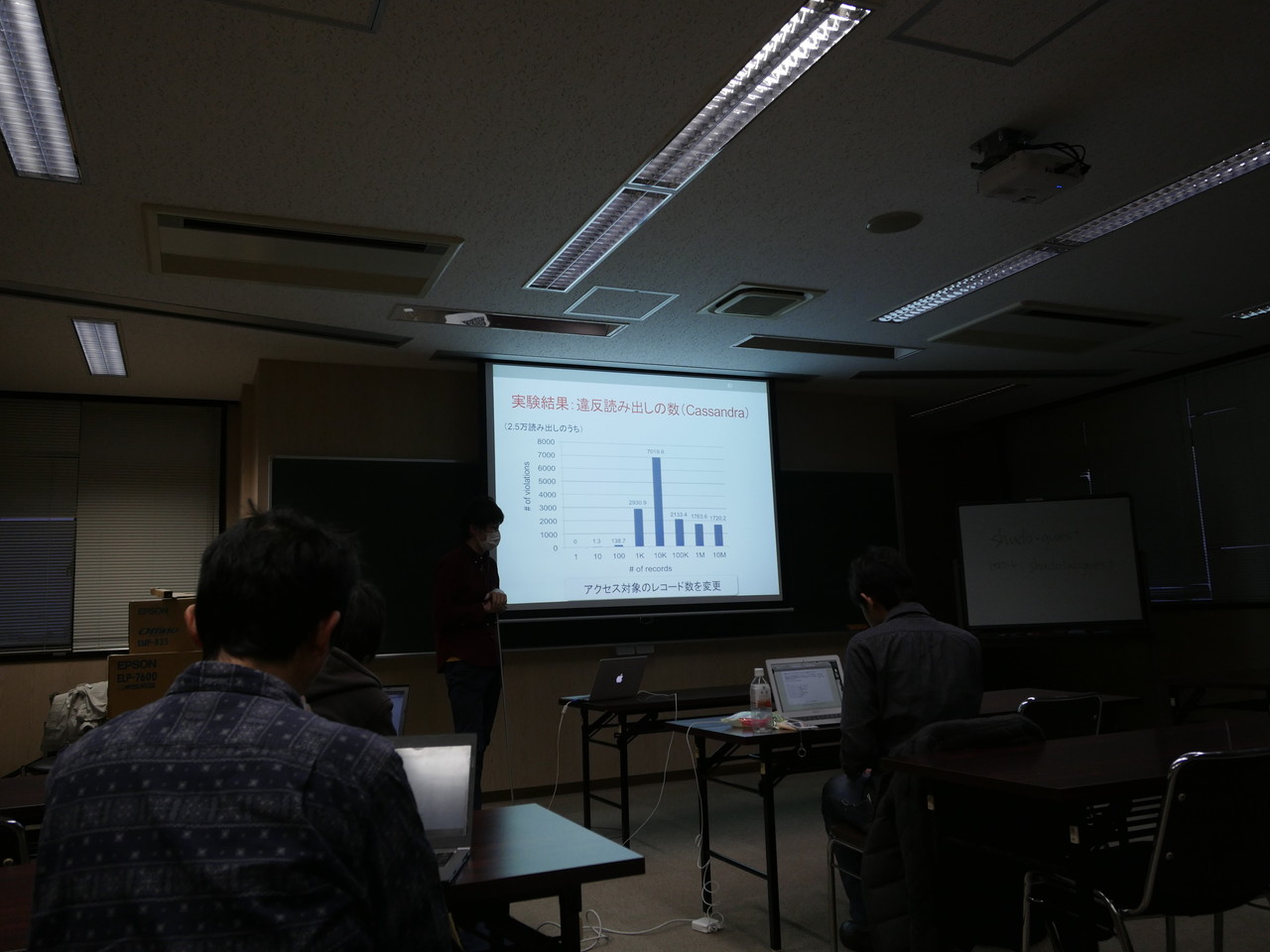
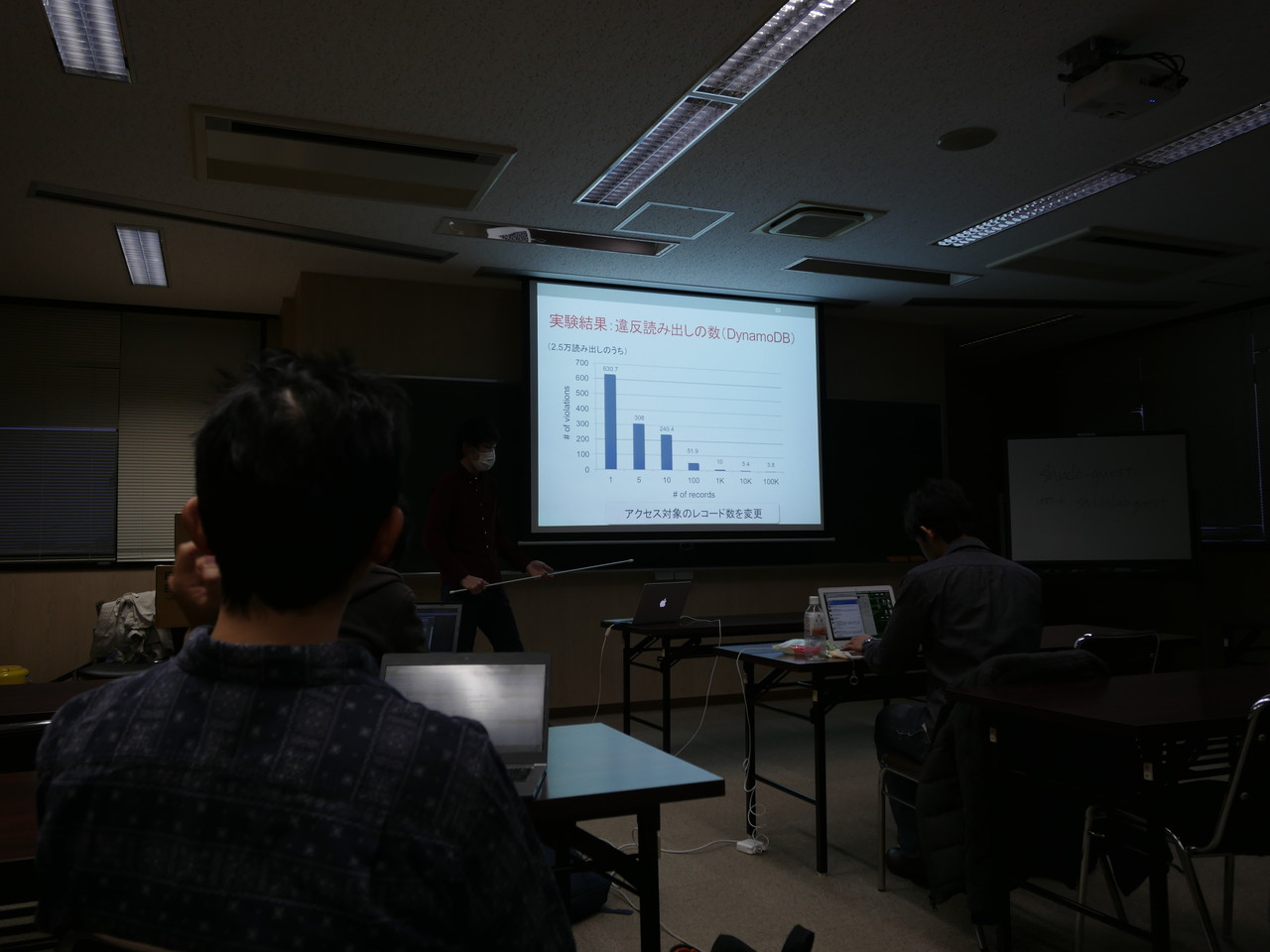
- 実験対象: CassandraとDynamoDB
- Cassandra: 直感と反してアクセス範囲が狭いときに違反がほとんどない。
- DynamoDB: 直感どおりアクセス範囲が広ければ違反が減っていく。
- 既存研究とのちがい: 測定ワークロードを限定しないところ。

[2016-03-21 18:03]
[2016-03-21 18:05]
@kumagi

- twitterやfacebookでばらさないようにということだったので
- 要約すると「副業してないといえる10の理由」という感じか。
- 才能の無駄遣いだなぁと思う一方、楽しそうだ。


[2016-03-21 18:17]


懇親会
大岡山周辺のお店は(おそらく学会の影響で)どこも満席のため、緑ヶ丘の「ちゃんこ芝松」へ。

















腰痛はひどくもならず無事帰宅。

















